for-loop 는 이제 그만 안녕
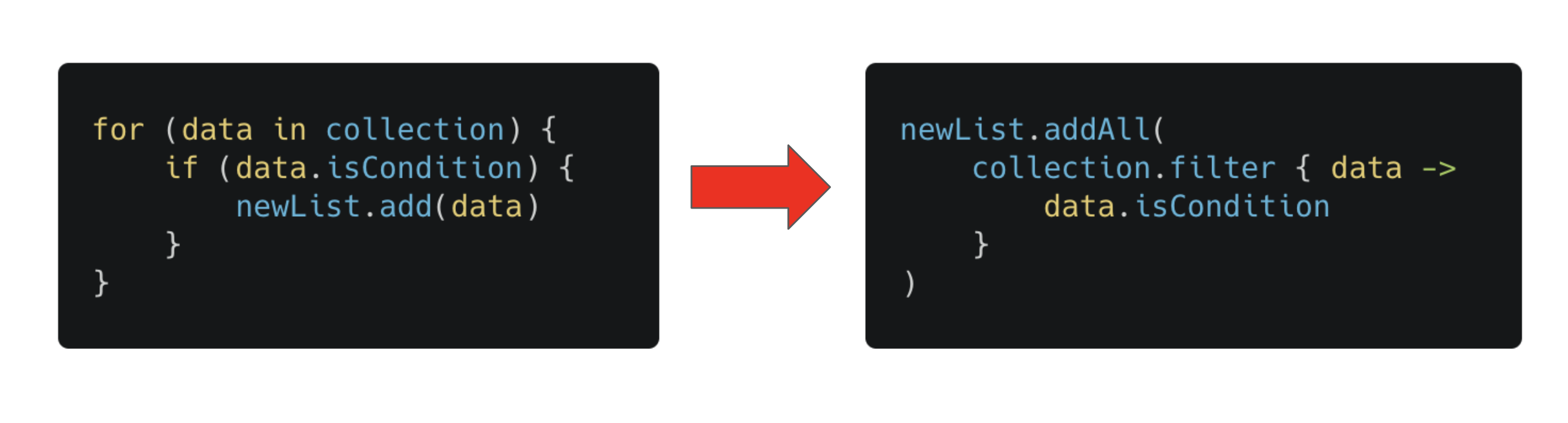
제가 코드리뷰할 때 보통 왼쪽 코드를 오른쪽으로 고치는 것을 권장합니다.
코틀린에서 제공하는 기본적인 API를 최대한 활용하는 것을 선호하고 반복문을 최대한 지양하는데,
그 이유는 바로 코틀린이 함수형 프로그래밍 언어이기 때문입니다.
함수형 프로그래밍 언어에서 For 반복문을 지양하는 이유
일단 이유는 크게 3가지가 있습니다.
- 명령형 프로그래밍 vs 선언형 프로그래밍
- 불변형 객체를 통한 원자성 유지
- 추상화를 통한 안정성 추구
명령형 프로그래밍 vs 선언형 프로그래밍
명령형은 어떻게 해야하는지에 초점이 맞춰진 프로그래밍이라면
선언형은 무엇을 해야하는지에 초점을 맞추는 프로그래밍 방식입니다.

왼쪽의 반복문 예제는 반복문을 돌면서 어떻게 데이터를 넣을지를 설명하는 코드라면
오른쪽 filter 예제는 어떤 데이터를 넣을지에 초점을 맞춘 코드라고 할 수 있습니다.
찾아보면 다들 선언형 프로그래밍이 가독성이 좋다고하고 저도 동의하지만..
사실익숙한 코드가 더 잘 읽히는 법이라 가독성 부분에서는 개인차가 존재한다고 생각합니다.
불변형 객체를 통한 원자성 유지
자바에서는 ArrayList를 이용해서 리스트를 관리하는 경우가 많았지만
Kotlin에서는 매번 새로운 불변형 List를 넘기는 식으로 관리하곤 합니다.
만약 반복문 안에서 MutableList를 이용해서 조작하면 원자성이 깨질 수 있습니다.
원자성이란?
원자성이란 완전하고 견고한 상태이거나 아니면 아예 실패하는 실패 원자성(failure atomicity) 을 의미합니다.
쉽게 말해 성공하면 깔끔하게 성공하거나, 실패하면 완전히 실패하는 성질로
실패했는데 상태가 변해있으면 원자성을 유지하지 못한 것이라 할 수 있습니다.
깔끔하게 완전히 실패하면 다시 시도하거나 취소하여 실패의 영향이 전파되지 않도록 할 수 있습니다.
예제를 봅시다.

실패했는데 왼쪽의 경우는 newList가 변해있지만 오른쪽의 경우는 변해있지 않습니다.
반복문을 사용하지 않고 불변형 객체를 넘기는 것으로 실패의 영향을 남기지 않을 수 있습니다.
추상화를 통한 안정성 추구
반복문에서는 종료 조건, 비교 조건, 반복 시점 등 한가지만 살짝 바뀌어도 깨지기 쉽습니다.
반복문을 사용하는 대신 추상화된 함수를 검증 후 재사용하는 편이 좋습니다.
결과적으로 언어에서 제공한 검증된 API를 사용하는 편이 훨씬 안정된다는 의미가 됩니다.
만약 검증된 API가 없다면 새로운 연산자를 만들어 검증하고 해당 연산자를 재사용 하는 것이 좋습니다.
리스트가 너무 커서 성능이 떨어진다면?
반복문을 사용하는 이유 중에 리스트가 너무 커서 성능상의 이유로
filter, map 등 리스트 연산자를 사용하지 않는 경우가 있습니다.
for (data in collection) {
// 조건에 맞으면 데이터 변환
if (data.isCondition) {
newList.add(NewData.from(data))
}
// N개의 아이템을 찾으면 종료
if (newList.size >= N) {
break
}
}
위의 반복문을 for-loop를 사용하지 않도록 바꾸면 아래와 같습니다.
newList.addAll(
collection.filter {
data.isCondition
}.map {
NewData.from(data)
}.take(N)
)
리스트의 크기가 크지 않다면 큰 문제가 되지 않겠지만 크기가 아주 크다면 얘기가 다릅니다.
크기가 큰 리스트에서 filter, map 등을 이용하여 리스트 전체를 여러번 탐색하게 되면
심각한 성능저하로 이어질 수 있습니다.
이런 성능저하를 피하고자 반복문을 사용하게 되는 경우도 있겠지만
이러한 문제는 Sequence 를 이용해서 해결할 수 있습니다.
Sequence를 이용한 lazy한 연산
newList.addAll(
collection.asSequence().filter {
data.isCondition
}.map {
NewData.from(data)
}.take(N)
.toList()
)
.asSequence() 와 .toList()를 붙이는 것만으로도 쉽게 해결할 수 있습니다.
Sequence는 filter, map 등의 연산자가 모든 리스트를 모두 훑으며 진행되는 것이 아니라
위의 반복문처럼 각 원소별로 filter, map 연산자가 lazy하게 동작하여
리스트 전체를 돌지 않고 해결하므로 리스트의 크기가 아무리커도 성능저하가 일어나지 않습니다.
자세한 내용은 코틀린 공식 문서를 참고하시고
나중에 기회된다면 Sequence에 대해 자세히 다뤄보도록 하겠습니다.